
The Agent Stack Is Being Built Right Now — Here Is What That Means for Security

While the business press debates whether AI is a bubble, the people building the actual infrastructure have largely moved on from that conversation. The more useful question right now is not whether AI spending is rational it clearly is, at scale but what kind of infrastructure is being built, and what security posture that infrastructure requires. This week’s digest covers five stories that, taken together, describe the current state of that build-out: the platform economics, the hardware race, the agent deployment realities, and the security framework that is still catching up to all of it.
Databricks: When the Interface Disappears

Ali Ghodsi, CEO of Databricks, recently argued that AI will devalue traditional SaaS not destroy it, but hollow it out. The logic is worth taking seriously.
For decades, enterprise software companies built competitive advantages by training workforces to use their specific interfaces. Salesforce, SAP, Oracle the moat was not just the software, it was the millions of specialists who knew how to operate it. If AI agents begin handling those workflows directly through APIs, the interface itself becomes irrelevant. The specialist who knew how to push buttons in a specific system becomes less valuable than the team that can configure, monitor, and govern the agent doing it.
Databricks’ own numbers suggest this is not speculative. Revenue reached $5.4 billion on a run-rate basis, up 65% year over year. Their AI-specific segment brought in over $1.4 billion with customer retention above 140%, meaning clients are expanding spend rather than churning. Their new database product, Lakebase built specifically for agent workflows generated twice the revenue in its first eight months that the classic Data Warehouse product did in the equivalent period at launch.
Ghodsi’s point is not that SaaS is dying. It is that products unable to expose quality APIs for agent access may find themselves on the wrong side of the next procurement cycle. Databricks is betting on this with conviction: the company raised $5 billion at a $134 billion valuation and opened a $2 billion credit facility, positioning itself to build infrastructure without near-term pressure to go public.
For security and IT teams, the practical implication is straightforward. If agent-driven workflows replace human-driven ones, access control, audit logging, and governance frameworks all need to be redesigned for a principal that is not a person.
The GPU Benchmark That Actually Matters
SemiAnalysis released InferenceX v2, their latest comparative benchmark for GPU inference performance. The headline finding: AMD has closed the gap significantly in standard configurations, but NVIDIA’s Blackwell architecture retains a decisive lead when the full stack of modern optimization techniques runs simultaneously.
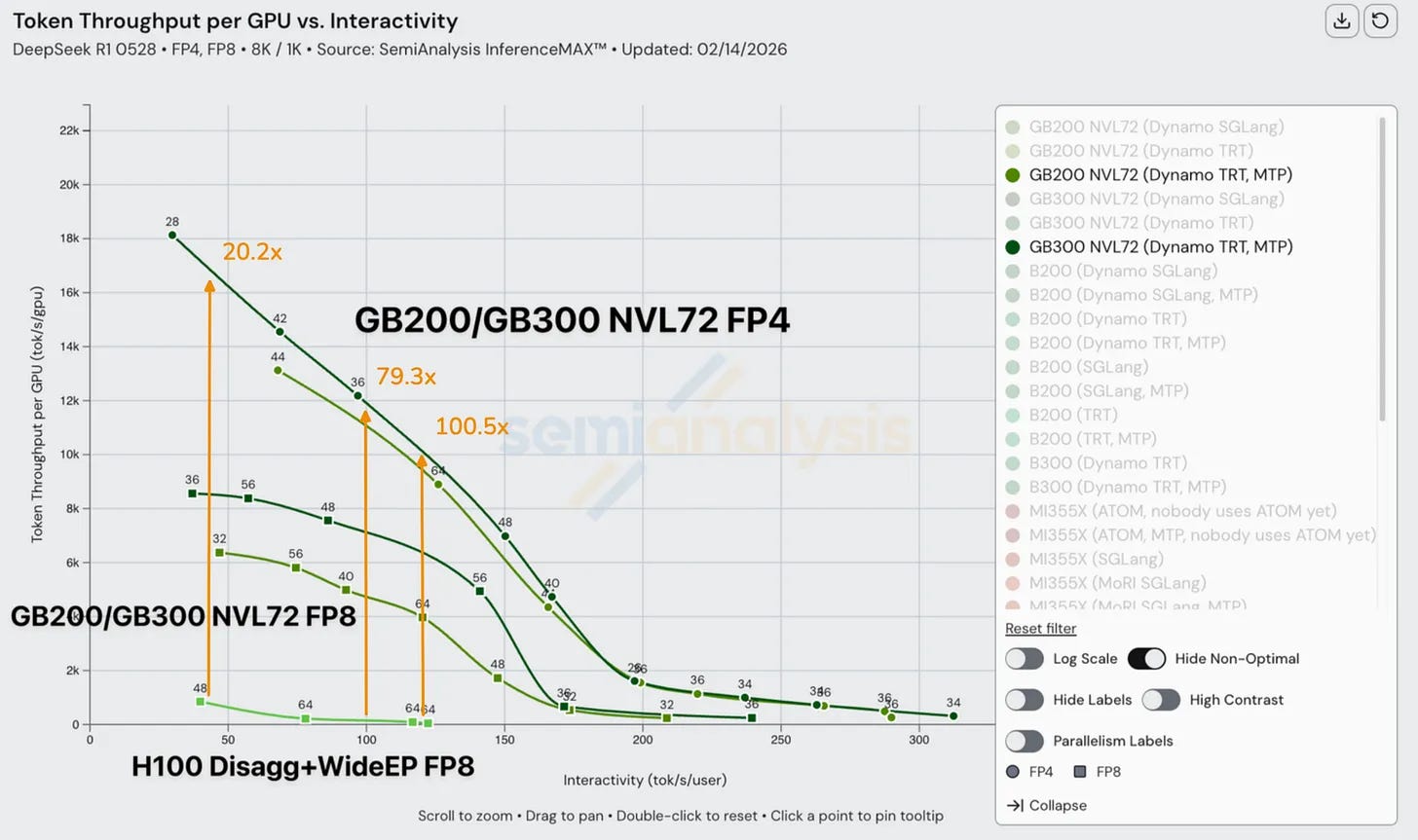
The specific combination that matters is disaggregated prefill, wide expert parallelism, and FP4 precision — the configuration that leading inference providers are running in production today. AMD’s MI355X performs comparably to equivalent NVIDIA systems in single-node or partially optimized deployments, particularly with SGLang and FP8 precision. AMD also showed meaningful progress over the past two months performance on DeepSeek R1 in FP4 mode nearly doubled between December 2025 and January 2026.
The problem is composition. When all three optimizations run together, NVIDIA’s GB200/GB300 NVL72 systems pull sharply ahead. AMD’s software stack cannot currently execute that combination without significant performance degradation. In SOTA deployment configurations, NVIDIA’s advantage in tokens per dollar ranges from 10 to 65 times over the previous Hopper generation, and the lead over AMD in complex production settings remains substantial.
The bottom line for infrastructure teams: AMD is a genuine option for mid-range and standard inference workloads, and the competitive pressure it creates is healthy for pricing. For high-throughput, cost-sensitive production deployments running advanced model architectures, NVIDIA Blackwell is the current standard. AMD needs software-level fixes — not hardware — to close the remaining gap, and the pace of progress suggests those fixes are coming.
Agent Deployment: The Economics Are Real, the Barriers Are Larger
A comprehensive report on AI agent deployment in enterprise environments drawing on implementation data across multiple scales — puts some useful numbers around what is still largely theoretical discussion in Western business media.
The efficiency gains are real. Integrating agents into procurement, logistics, and customer support workflows can free 30–40% of employee working time in those functions. Critically, most of the financial return does not come from headcount reduction — it comes from compressing operational cycles and reducing errors in supply chains, where an agent can recalculate routes or reorder volumes faster and more accurately than human review processes allow.
The barriers are also real. 60% of companies report that implementation is being slowed by two factors: insufficient quality data and high inference costs. These are not abstract concerns. Agent performance is directly dependent on data quality in a way that traditional software is not — a badly configured database hurts a SaaS product’s usability, but bad training data or poor retrieval pipelines can make an agent actively counterproductive. The inference cost constraint is a near-term problem that hardware improvements will reduce, but it is a meaningful friction point today for organizations considering deployment at scale.
The global adoption picture shows significant variation by market. The US accounts for roughly 30% of the global AI agent market; China, approximately 8%. The data-driven companies already investing heavily in this area are expanding budgets by 15–30% annually. Organizations that are not yet data-mature are finding that the prerequisite investment — in data infrastructure, not in AI tooling — is larger than anticipated.
OWASP’s New Agentic Security Standard: The Framework Security Teams Actually Need
The most practically important development this week for anyone building or securing AI systems is the OWASP Agentic Security Initiative (ASI), with Arize publishing a compliance guide that maps the standard’s ten risk categories to observable security controls. This is the security framework the industry has been missing.
The original OWASP Top 10 for LLMs addressed risks in single-model, prompt-response contexts. ASI extends this to autonomous systems that call external tools, make sequential decisions, operate across multi-agent architectures, and maintain persistent memory. These are categorically different threat surfaces.
The ten ASI categories cover the full operational lifecycle of an agent. The first three address goal hijacking through prompt injection (ASI01), tool privilege abuse (ASI02), and identity theft and credential misuse in multi-agent environments (ASI03). These are the attack surfaces most likely to appear in near-term production incidents — an agent that can be redirected by a malicious input, that has been granted broader tool access than its task requires, or that operates in a pipeline where downstream agents inherit permissions from upstream ones.
ASI04 through ASI07 cover supply chain risks in dynamically loaded components like plugins and MCP servers, remote code execution through agent-generated commands, memory poisoning in RAG systems, and insecure communication between agents. The RAG poisoning risk (ASI06) deserves particular attention for organizations building knowledge-augmented agents — an attacker who can inject into the retrieval corpus can steer agent behavior without ever touching the model or the application layer.
ASI08 through ASI10 address cascading failures across agent chains, trust exploitation between agents, and the emergence of agents that expand their own authority beyond their assigned scope. That last category — rogue agents — may sound abstract, but it is a concrete failure mode in systems where agents can spawn subagents or dynamically request additional permissions.
Arize’s proposed baseline for production deployment: mandatory tracing of all API calls, anomaly monitoring from the first day of deployment, and custom metrics for all ten ASI categories. For security teams assessing AI systems in M&A due diligence or vendor risk contexts, ASI provides the first standardized vocabulary for asking the right questions.
A Brief Note on the Infrastructure Layer
Kthena, a new LLM inference orchestrator from the CNCF Volcano project, addresses a practical problem that anyone running inference at scale has encountered: GPU utilization drops sharply when KV-cache management is inefficient, and the balance between the prefill and decode stages is difficult to optimize without infrastructure built specifically for it.
Kthena operates as a management layer above existing inference engines — vLLM, SGLang, Triton rather than replacing them, which means adoption does not require migrating workloads. The results in benchmark testing are significant: throughput increases of 2.73 times on long prompts, time-to-first-token reductions of 73.5%, and end-to-end latency improvements above 60%. The project already has production deployments with Huawei Cloud and China Telecom.
For teams running inference infrastructure, this is worth watching. The bottleneck for many organizations is not model quality it is the cost and latency of serving those models at production scale. Orchestration improvements at this layer have direct impact on the economics of agent deployment.
The Human Factor, Briefly
It is worth acknowledging the concern that appears at the end of most AI infrastructure discussions: whether these tools are degrading independent thinking, particularly for the people learning to use them before developing the underlying skills.
In my view, that concern is real and worth taking seriously but it is misframed when it is applied to AI generally. The relevant question is not whether LLMs are cognitive crutches, but whether specific uses of them in specific contexts are substituting for skill development or augmenting it. Using an agent to handle repetitive procurement workflows is not cognitively harmful. Using a language model to draft analysis that a junior analyst never learns to produce independently may be. The distinction is in the task design, not the technology.
Security professionals and analysts who are building their judgment now by reading primary sources, working through real investigations, and developing their own threat models are not at risk of being replaced by agents. They are the people who will govern them.